Documentation
1. Introduction
Le projet CycleVision3 a pour objectif d’analyser et de prédire les flux cyclistes dans la ville de Montpellier à l’aide de données issues de trois sources principales :
- VéloMagg : Historique des trajets réalisés avec le système de vélos en libre-service.
- Capteurs de flux cyclistes et piétons : Données collectées à partir de dispositifs installés aux points stratégiques de la ville.
- OpenStreetMap (OSM) : Données géographiques ouvertes, utilisées pour la cartographie et la contextualisation des trajets.
L’ambition du projet est de développer des visualisations interactives, notamment une carte prédictive des flux cyclistes, accessibles via un site web dédié. Ces outils visent à :
- Identifier les tendances de mobilité pour mieux comprendre les habitudes des usagers.
- Proposer des solutions pratiques afin d’optimiser les infrastructures urbaines et de promouvoir l’usage du vélo comme moyen de transport durable.
En combinant innovation technologique et impact sociétal, CycleVision3 s’inscrit dans une démarche adaptable à d’autres contextes urbains. Ce projet contribue ainsi à la réflexion autour de la mobilité intelligente et durable, répondant aux enjeux croissants des villes contemporaines.
2. Project Setup
2.1 Structure du projet
La structure du projet est conçue pour garantir une séparation claire des composantes essentielles à l’analyse et à la création des visualisations. Voici un aperçu de l’organisation des fichiers et répertoires :
Voir la structure
main/ # Répertoire principal du projet
├── .github/workflows/ # Automatisation des actions GitHub
│ ├── update_and_deploy.yml # Configuration pour les mises à jour et déploiements automatiques
├── Cycle3/ # Dossier principal avec les codes de programme
│ ├── analyse_donnee/ # Scripts pour l'analyse exploratoire des données
│ │ ├── cache/
│ │ ├── __init__.py
│ │ └── statistique.py
│ ├── docs/ # Configuration et génération de la documentation avec Sphinx
│ │ ├── build/html/
│ │ ├── cache/
│ │ ├── conf.py
│ │ ├── make.bat
│ │ ├── Makefile
│ │ ├── index.rst
│ │ └── ... # D'autres fichiers au format .rst
│ ├── images/ # Images utilisées dans le projet
│ ├── map/ # Scripts pour les cartes interactives
│ │ ├── __init__.py
│ │ ├── carte.py
│ │ ├── map.py
│ │ └── map_trajet_BD.py
│ ├── prediction/ # Scripts pour les cartes de prediction
│ │ ├── __init__.py
│ │ └── prediction.py
│ ├── vidéo/ # Scripts pour les video
│ │ ├── __init__.py
│ │ └── vidéo.py
│ ├── visualisation/ # Résultats des visualisations
├── cache/
├── data/ # Données pour l'analyse
│ ├── extracted/ # Données extraites
│ ├── CoursesVelomagg.csv # Données des trajets VéloMagg
│ ├── video.csv # Données vidéo
│ └── video_avec_coord.csv # Données vidéo enrichies avec coordonnées
├── docs/ # Contenu et configuration du site web
│ ├── _freeze/
│ ├── cache/
│ ├── docu_files/ # Fichiers affichés sur la page "Documentation"
│ ├── ... # Fichiers affichés pour d'autres pages
│ ├── shiny_app/ # Application interactive pour explorer les données
│ ├── styles.css # Feuille de style pour le site
│ └── ... # Autres fichiers nécessaires
├── roadmap/ # Documentation de la planification initiale du projet
├── slide/ # Fichiers liés à la présentation finale
│ ├── cache/
│ ├── images/
│ ├── slide_files/libs/
│ ├── slide.html # Version exportée des diapositives
│ ├── slide.qmd # Contenu principal des diapositives
│ ├── slides-styles.scss # Feuille de style pour la personnalisation des diapositives
│ ├── slide.css # Feuille de style pour la personnalisation des diapositives
│ └── ... # Autres fichiers nécessaires
├── src/ # Répertoire contenant le code source
│ ├── __init__.py
│ ├── donnée.py # Fonctions de traitement des données
│ ├── fonctions_basedonnees.py # Fonctions pour les bases de données
│ └── gestion_donnee.py # Classe "GestionnaireDonnees" pour le traitement des données
├── test/ # Répertoire contenant le code pour les tests
├── .gitignore # Liste des fichiers ignorés par Git
├── LICENCE # Informations sur la licence du projet
├── README.md # Résumé et instructions pour exécuter le projet
└── requirements.txt # Liste des bibliothèques et dépendances nécessaires2.2 Installation et dépendances
Avant de commencer le développement et l’analyse des données, il est nécessaire de configurer l’environnement de travail en installant toutes les dépendances requises. Suivez les étapes ci-dessous pour configurer rapidement et exécuter le projet :
- Cloner le dépôt
Clonez le répertoire du projet et accédez-y
git clone https://github.com/mscaia/PROJ_HAX712X.git
cd PROJ_HAX712X- Configurer l’environnement
Créez et activez un environnement virtuel avec Conda
conda create --name Cycle3 python=3.9.18
conda activate Cycle3Installez les dépendances listées dans requirements.txt
pip install -r requirements.txt- Exécuter les scripts
Pour plus de détails sur les visualisations et les fonctionnalités avancées, consultez la section 9. Guide de l’utilisateur.
2.3 Configuration des fichiers
Le projet est configuré de manière à utiliser Quarto pour la création du site web interactif. Toute la documentation a été initialement rédigée en utilisant des fichiers .qmd, en cohérence avec le reste du site.
Le fichier _quarto.yml contient les paramètres de configuration du projet Quarto, tandis que le fichier index.qmd contient le contenu principal de la page d’accueil du site.
2.4 Base de données et traitement des données
Les principaux jeux de données sont stockés dans le répertoire data/ et comprennent :
- CoursesVelomagg.csv : Historique des trajets en vélos libres.
- video.csv et video_avec_coord.csv : Données vidéo pour l’analyse spatiale.
Le traitement des données est assuré par les scripts situés dans le répertoire src/ :
- donnée.py : Fonctions pour gérer et structurer les données brutes.
- fonctions_basedonnees.py : Fonctions spécifiques aux bases de données.
- gestion_donnee.py : Classe principale pour le traitement et la transformation des données.
Les résultats de l’analyse sont exploités dans le répertoire Cycle3/, qui contient notamment des scripts pour :
- L’analyse exploratoire des données (
analyse_donnee/).
- La visualisation cartographique (
map/).
- La modélisation prédictive (
prediction/). - La génération de vidéos (
video/).
2.5 Exécution du projet
L’exécution du projet génère des visualisations interactives et des cartes prédictives grâce à :
- Folium : Création de cartes interactives.
- Matplotlib : Graphiques statistiques.
Les résultats sont stockés dans Cycle3/visualisation/ et incluent des cartes des trajets et des prévisions de trafic.
2.6 Documentation et tests
Pour garantir la qualité du code, le projet intègre :
- Tests Unitaires : Vérification des fonctionnalités principales.
- Documentation Technique : Rédigée avec Quarto pour détailler les API, les méthodes et les résultats. Une tentative de création avec Sphinx a été effectuée, mais elle n’a pas abouti en raison de difficultés techniques.
3. Description des Données
L’analyse repose sur l’exploitation de trois ensembles de données principaux, chacun jouant un rôle clé dans l’étude des trajets cyclistes à Montpellier :
Données des trajets en vélos en libre-service (VéloMagg) : Ces données fournissent des informations détaillées sur l’utilisation des vélos en libre-service dans la métropole de Montpellier. Elles constituent une base essentielle pour analyser les tendances et les flux de déplacements cyclistes.
Source: Trajets à vélos en libre-serviceDonnées de comptage cycliste et piéton : Ces données, collectées par des capteurs placés à divers emplacements stratégiques, permettent de mesurer les flux de cyclistes et de piétons dans la ville. Elles enrichissent l’analyse en fournissant une perspective quantitative sur la fréquentation des infrastructures.
Source: Comptages vélo et piéton issus des compteurs de véloDonnées géographiques OpenStreetMap (OSM) : Ces données géographiques offrent une cartographie précise des rues, pistes cyclables et points d’intérêt de la ville. Elles sont cruciales pour la visualisation et la spatialisation des trajets étudiés.
Source: OpenStreetMap
Ces trois ensembles de données, permettent une analyse approfondie et multidimensionnelle du trafic cycliste à Montpellier.
4. Workflow du Projet
4.1 Prétraitement et Nettoyage des Données
Étapes réalisées :
Le nettoyage et le prétraitement des données ont constitué une étape fondamentale pour assurer la qualité et la cohérence des données utilisées dans l’analyse. Les principales actions entreprises sont les suivantes :
- Validation des données : Identification et traitement des anomalies, telles que les valeurs aberrantes et les doublons, avec une gestion des valeurs manquantes en fonction de leur impact sur l’analyse.
- Formatage temporel et géographique : Conversion des champs de dates pour permettre une analyse chronologique, et standardisation des adresses et coordonnées géographiques pour optimiser la géolocalisation.
Cette phase a permis de préparer des données propres et fiables, essentielles pour l’analyse et la création des visualisations.
4.2 Visualisation et Cartographie du Trafic
Étapes réalisées :
Les données traitées ont été intégrées dans des visualisations interactives et des cartes dynamiques pour illustrer le trafic cycliste à Montpellier. Les actions clés incluent :
- Création de cartes interactives : Utilisation de la bibliothèque
Foliumpour développer une carte dynamique présentant les stations de vélos, les itinéraires fréquentés, et les zones de densité de trafic. - Calcul des itinéraires : Emploi de la bibliothèque
OSMnxpour déterminer les itinéraires entre les stations, mettant en évidence les parcours les plus utilisés et permettant l’analyse des variations temporelles du trafic.
Ces visualisations ont été des outils essentiels pour la compréhension des tendances du trafic cycliste, facilitant l’analyse et la prise de décisions éclairées pour les phases suivantes du projet.
4.3 Développement de l’Interface Web
Le projet s’est concrétisé par la création d’un site web interactif développé avec Quarto, intégrant :
- Les visualisations interactives produites lors de l’analyse.
- Une carte prédictive du trafic cycliste, permettant d’estimer les flux de vélos pour le lendemain en fonction des données historiques.
Cette interface a été conçue pour offrir une navigation fluide et intuitive, rendant les résultats accessibles aux utilisateurs de vélos. Elle constitue un outil complet pour l’analyse des données et la planification urbaine, tout en favorisant la promotion de la mobilité durable.
5. Pipeline de Traitement des Données
Le traitement des données est un élément central du projet CycleVision3, transformant les données brutes en informations exploitables pour l’analyse et la modélisation du trafic cycliste. La méthodologie adoptée repose sur une structure modulaire, garantissant flexibilité et robustesse. Les étapes principales du pipeline sont détaillées ci-dessous :
5.1 Acquisition des données
Les ensembles de données ont été obtenus à partir de sources officielles :
- Données VéloMagg : Historique des trajets réalisés via le système de vélos en libre-service.
- Comptages cyclistes et piétons : Données de comptage obtenues par des capteurs installés à des points stratégiques de la ville.
- Données OpenStreetMap (OSM) : Informations géographiques utilisées pour la cartographie des trajets.
Les fichiers ont été extraits sous les formats .csv et .json et chargés à l’aide de la bibliothèque pandas. Une validation initiale a été réalisée pour vérifier l’intégrité des fichiers (taille, colonnes attendues, etc.).
5.2 Prétraitement
L’étape de prétraitement vise à rendre les données prêtes pour l’analyse. Les principales opérations incluent :
- Nettoyage des données : Suppression des valeurs manquantes et des doublons afin de garantir la cohérence des données.
- Transformation des variables : Normalisation des données temporelles pour assurer une harmonisation des différents jeux de données.
Ces étapes ont permis de préparer un jeu de données fiable pour l’analyse et la modélisation.
5.3 Analyse exploratoire
Une analyse préliminaire des données a permis de dégager plusieurs tendances importantes :
- Analyse temporelle des flux : Identification des variations du trafic cycliste selon l’heure, le jour et le mois.
- Cartographie du trafic : Création de cartes interactives avec
Foliumpour visualiser les zones de forte densité de trafic. - Visualisation des variations de trafic : Observation des fluctuations de la densité du trafic à travers la ville.
Cette analyse exploratoire a guidé les choix méthodologiques pour les étapes suivantes, notamment la modélisation du trafic.
5.4 Modélisation
Un algorithme de prédiction du trafic cycliste a été conçu en prenant en compte plusieurs variables clés :
- Données historiques des trajets : Utilisation des trajets passés pour identifier des tendances.
- Localisation et fréquence des trajets : Analyse des points de départ et d’arrivée, ainsi que des fréquences de passage.
Le modèle repose sur l’analyse des données disponibles pour estimer les flux futurs de trafic, en se basant sur les tendances observées dans les trajets passés et leur répartition géographique.
5.5 Visualisation
Les résultats du projet sont présentés à travers diverses visualisations interactives, permettant une exploration approfondie des données :
- Cartes des trajets : Visualisation des trajets réalisés par les cyclistes, avec une mise en évidence des zones de forte densité de trafic.
- Cartes prédictives : Représentation des trajectoires prévues pour le trafic cycliste basé sur les données historiques.
- Carte des stations de vélos de Montpellier : Localisation des stations de vélos en libre-service à travers la ville, permettant une meilleure compréhension des points d’accès aux vélos.
- Visualisation vidéo : Une vidéo illustrant l’évolution du trafic cycliste sur une journée complète, générée à partir des données du projet.
Toutes ces visualisations sont accessibles directement via le site web interactif du projet, offrant ainsi une interface intuitive pour l’exploration des flux cyclistes et des prédictions.
5.6 Intégration
Le pipeline a été conçu pour être flexible et évolutif afin de répondre aux besoins futurs du projet :
- Portabilité : Le système peut être facilement adapté à d’autres villes disposant de systèmes de vélos en libre-service similaires, permettant ainsi une application étendue de la méthodologie.
- Scalabilité : Le pipeline est conçu pour intégrer de nouveaux types de données, tels que celles concernant la pollution de l’air ou les conditions météorologiques, pour affiner les prédictions et les analyses.
6. Documentation Technique du Projet
6.1 Bibliothèques utilisées
Dans le cadre de ce projet, plusieurs bibliothèques ont été utilisées pour répondre aux différents besoins techniques et analytiques. Voici une présentation des bibliothèques principales et leur rôle.
concurrent.futures.ThreadPoolExecutor
ThreadPoolExecutor est une fonctionnalité du module standard concurrent.futures pour exécuter des tâches en parallèle.Elle est utilisée pour optimiser le traitement des données et accélérer le rendu des animations dans le cadre de ce projet.
csv
La bibliothèque csv permet de lire et d’écrire des fichiers CSV, un format commun pour manipuler des données tabulaires.Nous avons utilisé
csv pour extraire et traiter les données brutes contenues dans des fichiers au format CSV. Cela est particulièrement utile pour manipuler des ensembles de données simples où une lecture ligne par ligne est nécessaire.
datetime
datetime est un module intégré pour manipuler les dates et les heures.Dans le projet, il est employé pour traiter les données temporelles des trajets cyclistes et synchroniser les animations avec les horodatages.
folium
folium est une bibliothèque dédiée à la création de cartes interactives.Nous avons utilisé
folium pour visualiser les trajets et itinéraires des vélos sur des cartes interactives, permettant une meilleure compréhension géographique des données.
functools.lru_cache
functools.lru_cache est une fonctionnalité de Python pour optimiser les performances.En mettant en cache les résultats des fonctions fréquemment appelées,
functools.lru_cache améliore les performances et réduit le temps de calcul pour des opérations répétées.
json
json est utilisée pour manipuler des données au format JSON, un standard de stockage et d’échange d’informations structurées.Nous utilisons
json pour lire et écrire des données structurées, notamment pour gérer les configurations et les résultats intermédiaires dans des fichiers légers.
matplotlib.animation.FuncAnimation et FFMpegWriter
Ces modules de la bibliothèque matplotlib.animation permettent de créer des animations et d’exporter celles-ci sous forme de fichiers vidéo.Dans le projet, ils sont utilisés pour générer des animations illustrant les variations temporelles du trafic cycliste et les enregistrer sous un format visuel accessible.
matplotlib.pyplot
matplotlib.pyplot est utilisée pour produire des graphiques statiques et des visualisations animées.Dans ce projet, elle permet de créer des graphiques dynamiques illustrant les trajectoires cyclistes et d’exporter ces visualisations sous forme de vidéos à l’aide des modules
FuncAnimation et FFMpegWriter.
networkx
networkx est une bibliothèque dédiée à la création, la manipulation et l’analyse de graphes complexes.Dans ce projet, elle est utilisée pour représenter et étudier les réseaux cyclistes, notamment pour visualiser les trajets et calculer les chemins les plus courts entre les nœuds.
numpy
numpy est une bibliothèque puissante pour effectuer des calculs numériques avancés, notamment des opérations matricielles.Les opérations matricielles et les calculs numériques complexes nécessaires à l’analyse des données sont simplifiés grâce à
numpy, qui garantit également des performances élevées.
os
os fournit des fonctions pour interagir avec le système d’exploitation, notamment pour gérer les fichiers et les répertoires.Nous avons utilisé
os pour gérer les chemins des fichiers, vérifier l’existence des répertoires, et manipuler les ressources locales du système.
osmnx
osmnx est utilisée pour le géocodage et l’analyse des réseaux géographiques.Cette bibliothèque permet d’extraire des données géographiques d’OpenStreetMap, de construire des graphes routiers, et d’analyser les itinéraires et les trajets cyclistes dans le cadre de ce projet.
pandas
pandas est essentielle pour manipuler et analyser des données tabulaires de manière efficace.pandas est utilisée pour nettoyer, transformer et analyser des ensembles de données complexes, offrant des fonctionnalités avancées comme le traitement des séries temporelles et des jointures de tables.
pooch
pooch facilite le téléchargement et la mise en cache des fichiers nécessaires à l’exécution du projet.Cette bibliothèque permet de garantir un accès fiable aux données externes en les téléchargeant automatiquement et en les stockant localement pour une réutilisation future.
re
La bibliothèque re permet de travailler avec des expressions régulières pour manipuler des chaînes de caractères.Grâce à
re, nous avons pu extraire des informations spécifiques des chaînes de caractères et nettoyer les données textuelles de manière efficace.
scikit-learn
scikit-learn fournit des outils pour l’analyse des données et du machine learning, nous l’utilisons implicitement dans l’application shiny.
shiny
shiny est une bibliothèque permettant de créer des applications web interactives pour mieux visualiser et analyser des données, il nous a permis ici de contourner l’aspect statique du site Quarto.
shinyswatch
shinyswatch est un module qui vient en complément de shiny et qui permet de personnaliser l’apparence des applications grâce à l’intégration de thèmes préconfigurés.
unicodedata
unicodedata est utilisée pour normaliser les chaînes de caractères Unicode.Cette bibliothèque est essentielle pour traiter les caractères spéciaux et garantir la cohérence des chaînes de caractères provenant de différentes sources.
zipfile
La bibliothèque zipfile permet de travailler avec des fichiers au format ZIP, un format couramment utilisé pour la compression et l’archivage de fichiers.Nous avons utilisé
zipfile pour extraire des fichiers compressés afin de récupérer les données nécessaires à notre projet. Cette bibliothèque offre une interface simple pour l’extraction, la création et la gestion des archives ZIP, ce qui facilite le traitement des données compressées.
6.2 Fonctions utilisées
6.2.1 Map
Fonctions de traitement des données
colonne(i, w_file)
Description:
Cette fonction permet d’extraire une colonne spécifique d’un fichier CSV. Elle prend en entrée un indice i, représentant la colonne à extraire, ainsi que le chemin du fichier w_file. La fonction ouvre le fichier, parcourt chaque ligne et récupère l’élément situé à la position i dans chaque ligne.
Paramètres:
- i (int) : L’indice de la colonne à extraire.
- w_file (str) : Le chemin d’accès au fichier CSV.
Retourne:
- L (list) : Une liste contenant les valeurs de la colonne spécifiée.
Code de la fonction:
def colonne(i, w_file):
L = []
with open(w_file) as f:
for line in f:
x = line.split(",")
L.append(x[i])
return LExemple d’utilisation:
Supposons un fichier data.csv contenant :
name,age,city
Alice,30,Paris
Bob,25,Lyoncolonne(1, "data.csv") retourne [30, 25].
arg(k, i, j, w_file)
Description:
Cette fonction extrait les données correspondant à une clé k dans un fichier CSV et retourne les valeurs des colonnes spécifiées par i et j.
Paramètres:
- k (str) : La clé utilisée pour filtrer les données.
- i (int) : L’indice de la colonne contenant les clés.
- j (int) : L’indice de la colonne à retourner.
- w_file (str) : Le chemin d’accès au fichier CSV.
Retourne:
- L (list) : Une liste contenant les valeurs correspondantes.
Code de la fonction:
def arg(k, i, j, w_file):
L = []
with open(w_file) as f:
for line in f:
x = line.split(",")
if x[i] == k:
L.append(x[j])
return LPour le fichier
data.csv ci-dessus, appeler arg("Alice", 0, 2, "data.csv") retourne [Paris].
Fonctions d’adresse et de géocodage
nettoyer_adresse_normalise(adresse)
Description:
Nettoie et normalise une adresse en supprimant les numéros au début, en normalisant les caractères Unicode..
Paramètres:
- adresse (str) : L’adresse à normaliser.
Retourne:
- adresse (str) : L’adresse nettoyée et normalisée.
Code de la fonction:
def nettoyer_adresse_normalise(adresse):
# Tenter de corriger l'encodage si nécessaire
try:
# Encode la chaîne en latin1 puis décode en utf-8
adresse = adresse.encode('latin1').decode('utf-8')
except (UnicodeEncodeError, UnicodeDecodeError):
pass # Ignore les erreurs d'encodage si elles se produisent
# Supprimer les numéros ou autres formats non pertinents (ex: 057 au début)
adresse = re.sub(r'^\d+\s*', '', adresse) # Enlève les numéros au début
# Normalisation des caractères Unicode
adresse = unicodedata.normalize('NFKD', adresse)
# Retourner l'adresse nettoyée et normalisée
return adresse # Enlever les espaces supplémentaires aux extrémitésExemple avant/après:
- Avant : " 12, Rue de la République "
- Après : "12 rue de la république"
coordonne(station)
Description :
La fonction coordonne utilise le géocodage pour obtenir les coordonnées géographiques (latitude, longitude) d’une station donnée dans la ville de Montpellier, France.
-
station(str) : Le nom de la station à géocoder.
-
latitude(float) : La latitude de la station. -
longitude(float) : La longitude de la station.
Code de la fonction :
def coordonne(station):
try:
# Recherche de l'emplacement en utilisant osmnx
location = ox.geocode(f"{station}, Montpellier, France")
return location[0], location[1]
except Exception as e:
print(f"Erreur pour la station {station}: {e}")
return None, NoneFonctions liées à la carte
gen_carte_trajet(ligne, G, m, index_colonne_départ, index_colonne_arrive,couleur)
Description:
Génère une carte interactive affichant le trajet le plus court entre deux points.
-
ligne(list) : Une ligne contenant les noms des stations de départ et d’arrivée. -
G(Graph) : Le graphe représentant le réseau de rues de la ville. -
m(Map) : L’objet de la carte sur lequel le trajet sera tracé. -
index_colonne_départ(int) : L’indice de la colonne contenant le nom de la station de départ. -
index_colonne_arrive(int) : L’indice de la colonne contenant le nom de la station d’arrivée. -
couleur(str) : La couleur de la ligne représentant le trajet.
Retourne:
- folium.Map (Map) : La carte mise à jour avec le trajet et les marqueurs des points de départ et d’arrivée..
Code de la fonction:
def gen_carte_trajet(ligne, G, m, index_colonne_départ, index_colonne_arrive,couleur):
# Essayer de géocoder les stations de départ et d'arrivée
try:
origin = ox.geocode(f"{ligne[index_colonne_départ]}, Montpellier, France") # Première colonne
destination = ox.geocode(f"{ligne[index_colonne_arrive]}, Montpellier, France") # Deuxième colonne
# Vérifier si le géocodage a réussi
if origin is None or destination is None:
print(f"Erreur de géocodage pour les stations : {ligne[index_colonne_départ]} ou {ligne[index_colonne_arrive]}")
return m
# Trouver les noeuds les plus proches de l'origine et de la destination
origin_node = ox.nearest_nodes(G, origin[1], origin[0]) # longitude, latitude
destination_node = ox.nearest_nodes(G, destination[1], destination[0]) # longitude, latitude
# Calculer l'itinéraire aller et retour
route = ox.shortest_path(G, origin_node, destination_node)
# Fonction pour convertir un itinéraire (liste de noeuds) en liste de coordonnées géographiques
def route_to_coords(G, route):
route_coords = []
for node in route:
point = (G.nodes[node]['y'], G.nodes[node]['x']) # latitude, longitude
route_coords.append(point)
return route_coords
# Obtenir les coordonnées pour l'itinéraire
route_coords = route_to_coords(G, route)
# Ajouter l'itinéraire aller (en rouge) à la carte
folium.PolyLine(locations=route_coords, color=couleur, weight=5, opacity=0.75).add_to(m)
# Ajouter des marqueurs pour l'origine et la destination
départ_lat, départ_lon = route_coords[0]
arr_lat, arr_lon = route_coords[-1] # Utiliser le dernier point pour l'arrivée
folium.Marker(location=[départ_lat, départ_lon], popup=f"{ligne[index_colonne_départ]},Départ").add_to(m)
folium.Marker(location=[arr_lat, arr_lon], popup=f"{ligne[index_colonne_arrive]},arrivé").add_to(m)
except Exception as e:
print(f"Une erreur est survenue : {e}")
return m
intensity_to_color(intens, min_in, max_in)
Description:
La fonction renvoie un code couleur pour une intensité donnée.
Paramètres:
- intens (int): L’intensité qu’on cherche à représenter. - min_in (int): L’intensité minimale à représenter. Elle correspond au minimum de l’échelle de couleur. - max_in (int): L’intensité maximale à représenter. Elle correspond au maximum de l’échelle de couleur.
Retourne:
- rgba({}, {}, {}, {}) (arg): Le code couleur RGB associé à l’intensité à représenter.
Code de la fonction:
def intensity_to_color(intens, min_in, max_in):
"""
Description:
La fonction 'intensity_to_color' renvoie un code couleur pour une intensité donnée.
Args:
intens : int
L'intensité qu'on cherche à représenter.
min_in : int
L'intensité minimale à représenter. Elle correspond au minimum de l'échelle de couleur.
max_in : int
L'intensité maximale à représenter. Elle correspond au maximum de l'échelle de couleur.
Returns:
'rgba({}, {}, {}, {})' : str
Le code couleur RGB associé à l'intensité à représenter.
"""
norm_in = (intens - min_in) / (max_in - min_in)
color = plt.cm.RdYlGn_r(norm_in) # Colormap GnYlRd(vert à rouge)
return 'rgba({}, {}, {}, {})'.format(int(color[0] * 255), int(color[1] * 255), int(color[2] * 255), 1)Exemple d’utilisation: Suppososns qu’on veuille représenter la valeur 12 sur une échelle allant de 6 à 18
Appelerintensity_to_color(12, 6, 18) retourne rgba(254, 254, 189, 1)
map_jour(j, style, jour)
Description:
La fonction génère une carte des intensités moyennes observées un jour de la semaine j.
Paramètres:
- j (int): Le numéro du jour de la semaine (entre 0 et 6) voulu.
- style (int): Le numéro (0 ou 1) correspondant au style voulu. 0 donnera une carte avec uniquement des points de différentes couleur et 1 donnera une carte avec ces points mais également la carte de chaleur (Heatmap) associée. - jour (str): Le jour de la semaine voulu (format Jour).
Retourne:
- La carte a été générée et sauvegardée sous le nom, nom (str, str) : Un message de validation de création de la carte et le nom sous lequel elle a été enregistrée.
Code de la fonction:
def map_jour(j, style,jour):# entrée 0-6 pour les jours de la semaine, 0-1 sans-avec chaleur
"""
Description:
La fonction 'map_jour' génère une carte des intensités moyennes observées un jour de la semaine j.
Args:
- j : int
Le numéro du jour de la semaine (entre 0 et 6) voulu.
- style : int
Le numéro (0 ou 1) correspondant au style voulu. 0 donnera une carte avec uniquement des points de différentes couleur et 1 donnera une carte avec ces points mais également la carte de chaleur (Heatmap) associée.
- jour : str
Le nom du jour correspondant (par exemple, "Lundi", "Mardi", etc.), utilisé pour nommer les fichiers générés.
Returns:
- 'La carte a été générée et sauvegardée sous le nom', nom : str, str
Un message de validation de création de la carte et le nom sous lequel elle a été enregistrée.
"""
data = mean_intens(j)
intensities = [d[0] for d in data]
min_in = min(intensities)
max_in = max(intensities)
# Centrer
ville = "Montpellier, France"
location = ox.geocode(ville)
m = folium.Map(location=location, zoom_start=12)
# Ajouter les points sur la carte
for intensity, coord in data:
lon, lat = coord[1], coord[0]# Inversion des valeurs
if abs(lon-location[0])<1 and abs(lat-location[1])<1:
color = intensity_to_color(intensity, min_in, max_in)
folium.CircleMarker(
location=[lon, lat],
radius=8,
popup=f"{intensity}",
color=color,
fill=True,
fill_color=color,
fill_opacity=0.6
).add_to(m)
legend_html ="""
<div style="
position: fixed;
bottom: 50px;
left: 50px;
width: 220px;
height: 120px;
background-color: white;
border: 2px solid grey;
z-index: 9999;
font-size: 14px;
padding: 10px;
">
<b>Nombre de passages:</b>
<div style="
height: 20px;
background: linear-gradient(to right, #008000, #f1fd4d, #f20000);
margin: 10px 0;
">
</div>
<div style="display: flex; justify-content: space-between;">
<span>Faible</span>
<span>Élevé</span>
</div>
</div>
"""
m.get_root().html.add_child(folium.Element(legend_html))
# Choix de chaleur ou non
if style==0:
nom=f'intensity_{j}.html'
m.save(f'./Cycle3/visualisation/{jour}/intensité/{nom}')
return "La carte a été générée et sauvegardée sous le nom", nom
else:
heat_data = [[coord[1], coord[0], intensity] for intensity, coord in data]
HeatMap(heat_data).add_to(m)
nom=f'intensity_{j}_heat.html'
m.save(f'./Cycle3/visualisation/{jour}/intensité/{nom}')
return"La carte a été générée et sauvegardée sous le nom", nom
map_jour_h(j, h,style,jour)
Description:
La fonction génère une carte des intensités moyennes observées un jour de la semaine j à une heure h.
Paramètres:
- j (int): Le numéro du jour de la semaine (entre 0 et 6) voulu. - h (int): Le numéro de l’heure (entre 0 et 23) voulue. - style (int): Le numéro (0 ou 1) correspondant au style voulu. 0 donnera une carte avec uniquement des points de différentes couleur et 1 donnera une carte avec ces points mais également la carte de chaleur (Heatmap) associée. - jour (str): Le jour voulu (format Jour).
Retourne:
- 'La carte a été générée et sauvegardée sous le nom', nom (str, str): Un message de validation de création de la carte et le nom sous lequel elle a été enregistrée.
Code de la fonction:
def map_jour_h(j, h,style,jour):# Entrée 0-6 pour les jours de la semaine, 0-1 sans-avec chaleur
"""
Description:
La fonction 'map_jour_h' génère une carte des intensités moyennes observées un jour de la semaine j à une heure h.
Args:
- j : int
Le numéro du jour de la semaine (entre 0 et 6) voulu.
- h : int
Le numéro de l'heure voulue (entre 0 et 23, 0 étant la plage horraire 00h00- 00h59).
- style : int
Le numéro (0 ou 1) correspondant au style voulu. 0 donnera une carte avec uniquement des points de différentes couleur et 1 donnera une carte avec ces points mais également la carte de chaleur (Heatmap) associée.
- jour : str
Le nom du jour correspondant (par exemple, "Lundi", "Mardi", etc.), utilisé pour nommer les fichiers générés.
Returns:
- 'La carte a été générée et sauvegardée sous le nom', nom : str, str
Un message de validation de création de la carte et le nom sous lequel elle a été enregistrée.
"""
data = mean_intens(j)
p=poids_par_h(j)
intensities = [d[0]*p[h][1]/100 for d in data]
min_in = min(intensities)
max_in = max(intensities)
# Centrer
ville = "Montpellier, France"
location = ox.geocode(ville)
m = folium.Map(location=location, zoom_start=12)
# Ajouter les points sur la carte
for intensity, coord in data:
newint=intensity*p[h][1]/100
lon, lat = coord[1], coord[0]# Inversion des valeurs
if abs(lon-location[0])<1 and abs(lat-location[1])<1:
color = intensity_to_color(newint, min_in, max_in)
folium.CircleMarker(
location=[lon, lat],
radius=8,
popup=f"{newint}",
color=color,
fill=True,
fill_color=color,
fill_opacity=0.6
).add_to(m)
# Générer la légende avec les couleurs correspondant aux min et max
min_color = intensity_to_color(min_in, min_in, max_in) # Couleur pour la valeur minimale
max_color = intensity_to_color(max_in, min_in, max_in) # Couleur pour la valeur maximale
legend_html = f"""
<div style="
position: fixed;
bottom: 50px;
left: 50px;
width: 200px;
height: 100px;
background-color: white;
border:2px solid grey;
z-index:9999;
font-size:14px;
padding: 10px;
">
<b>Nombre de passages:</b><br>
<i style="background: {min_color}; width: 20px; height: 10px; display: inline-block;"></i> {round(min_in, 2)}<br>
<i style="background: {max_color}; width: 20px; height: 10px; display: inline-block;"></i> {round(max_in, 2)}<br>
</div>
"""
m.get_root().html.add_child(folium.Element(legend_html))
# Choix de chaleur ou non
if style==0:
nom=f'intensity_{j}_{h}.html'
m.save(f'./Cycle3/visualisation/{jour}/intensité/{nom}')
return "La carte a été générée et sauvegardée sous le nom", nom
else:
heat_data = [[coord[1], coord[0], intensity] for intensity, coord in data]
HeatMap(heat_data).add_to(m)
nom=f'intensity_{j}_{h}_heat.html'
m.save(f'./Cycle3/visualisation/{jour}/intensité/{nom}')
return"La carte a été générée et sauvegardée sous le nom", nom
map_trajets(j, h,jour)
Description:
La fonction génère une carte des trajets parcourus un jour de la semaine j et à une heure h, ainsi que la probabilité qu’il soit de nouveau parcouru (en tenant compte des archives).
Paramètres:
j(int): Le numéro du jour de la semaine (entre 0 et 6) voulu.
h(int): Le numéro de l’heure (entre 0 et 23) voulue.
jour(str): Le jour voulu (format Jour).
Retourne:
- 'La carte a été générée et sauvegardée sous le nom', nom (str, str): Un message de validation de création de la carte et le nom sous lequel elle a été enregistrée.
Code de la fonction:
def map_trajets(j, h,jour):
"""
Description:
La fonction 'map_trajets' génère une carte des trajets parcourus un jour de la semaine j et à une heure h, ainsi que la probabilité qu'il soit de nouveau parcouru (en tenant compte des archives).
Args:
- j : int
Le numéro du jour de la semaine (entre 0 et 6) voulu.
- h : int
Le numéro de l'heure (entre 0 et 23) voulue.
- jour : str
Le nom du jour correspondant (par exemple, "Lundi", "Mardi", etc.), utilisé pour nommer les fichiers générés.
Returns:
- 'La carte a été générée et sauvegardée sous le nom', nom : str, str
Un message de validation de création de la carte et le nom sous lequel elle a été enregistrée.
"""
trajets=All_t[j][h]
stations_dict = {station[0]: station[1] for station in stations}
if j==0:
N=Nl
elif j==1:
N=Nma
elif j==2:
N=Nme
elif j==3:
N=Nj
elif j==4:
N=Nv
elif j==5:
N=Ns
else:
N=Nd
ville = "Montpellier, France"
location = ox.geocode(ville)
graphe = ox.graph_from_point(location, dist=10000, network_type="all", simplify=True)
carte = folium.Map(location=location, zoom_start=14)
# nb passages
edges_passages = defaultdict(int)
for trajet in trajets:
start, end = trajet[0]
intensity = min(trajet[1]/N, 1)
if start in stations_dict and end in stations_dict:
if start!=end:
lon_start, lat_start = stations_dict[start]
lon_end, lat_end = stations_dict[end]
# Trouver les nœuds les plus proches dans le graphe
start_node = ox.distance.nearest_nodes(graphe, lon_start, lat_start)
end_node = ox.distance.nearest_nodes(graphe, lon_end, lat_end)
# Calculer le chemin entre les deux nœuds
path = nx.shortest_path(graphe, start_node, end_node, weight="length")
# Ajouter chaque segment du chemin au compteur de passages
for u, v in zip(path[:-1], path[1:]):
edges_passages[(u, v)] += intensity
edges_passages[(v, u)] += intensity # Compte les passages dans les deux sens
# Couleurs en fonction du nb de passages
for (u, v), passage_count in edges_passages.items():
# Récup coordonnées des segments
coords = [
(graphe.nodes[u]['y'], graphe.nodes[u]['x']),
(graphe.nodes[v]['y'], graphe.nodes[v]['x'])
]
# Calcul de la couleur
if passage_count < 0.05:
color= "#0000ff" # bleu si faible
elif passage_count < 0.15:
color= "#008000" # vert
elif passage_count < 0.25:
color="#ffff00" # jaune
elif passage_count < 0.35:
color="#ff80000" # orange
elif passage_count < 1:
color="#ff0000" # rouge si fort
else:
passage_count=1
color="#000000"
# Ajouter le segment
folium.PolyLine(
locations=coords,
color=color,
weight=4,
opacity=0.8,
tooltip=f"Pourcentage: {passage_count*100}"
).add_to(carte)
# Ajout des stations comme marqueurs
for station in stations:
try:
(lon, lat) = station[1]
for k in name_sta:
if k[0]==station[0]:
name= k[1]
folium.Marker(
location=(lat, lon),
popup=f"{name}: {lon}, {lat}",
icon=folium.Icon(color="gray")
).add_to(carte)
except Exception as e:
print(f"Erreur lors de l'ajout de la station {station}: {e}")
# légende
legend_html = """
<div style="
position: fixed;
bottom: 50px;
left: 50px;
width: 200px;
height: 200px;
background-color: white;
border:2px solid grey;
z-index:9999;
font-size:14px;
padding: 10px;
">
<b>Pourcentage de chance que le trajet soit parcouru:</b><br>
<i style="background: #0000ff; width: 20px; height: 10px; display: inline-block;"></i> Très faible (<5%)<br>
<i style="background: #008000; width: 20px; height: 10px; display: inline-block;"></i> Faible (5%-14%)<br>
<i style="background: #ffff00; width: 20px; height: 10px; display: inline-block;"></i> Modéré (15%-24%)<br>
<i style="background: #ff8000; width: 20px; height: 10px; display: inline-block;"></i> Fort (25%-34%)<br>
<i style="background: #ff0000; width: 20px; height: 10px; display: inline-block;"></i> Très fort (> 34%)<br>
<i style="background: #000000; width: 20px; height: 10px; display: inline-block;"></i> Sûr (1)<br>
</div>
"""
carte.get_root().html.add_child(folium.Element(legend_html))
# Sauvergarder la carte
nom = f"trajets_couleurs_cumulées_j{j}_h{h}.html"
carte.save(f'./Cycle3/visualisation/{jour}/Trajetscouleurs/{nom}')
return f"Carte enregistrée sous '{nom}'."Fonctions utilitaires
pd_to_datetime(df, colonne_date)
Description:
Convertit une colonne de dates dans un DataFrame pandas en un format datetime, crée une nouvelle colonne avec uniquement la date, et supprime la colonne d’origine.
Paramètres:
- df (DataFrame) : DataFrame Pandas.
- colonne_date (str) : Nom de la colonne à convertir.
Retourne:
- df (pandas.DataFrame) : Le DataFrame modifié avec une colonne ‘Date’ contenant les dates extraites, et sans la colonne d’origine colonne_date..
Code de la fonction :
def pd_to_datetime(df, colonne_date):
df = df.dropna()
df[colonne_date] = pd.to_datetime(df[colonne_date])
df['Date'] = df[colonne_date].dt.date
df = df.drop(columns=[colonne_date])
return df
jour_semaine(j)
Description:
La fonction renvoie une liste des intensités et leurs coordonnées qui ont été mesurées à une date correspondant au jour de la semaine j.
Paramètre:
- j (int) : Le numéro du jour de la semaine (entre 0 et 6) voulu.
Retourne:
- L (list) :Une liste contenant toutes les données étant rattachées à une date correspondant au jour de la semaine voulu. Les données sont l’intensité et les coordonnées auxquelles elle est liée.
Code de la fonction:
def jour_semaine(j):
"""
Description:
La fonction 'jour_semaine' renvoie une liste des intensités et leurs coordonnées qui ont été mesurées à une date correspondant au jour de la semaine j.
Args:
- j : int
Le numéro du jour de la semaine (entre 0 et 6) voulu.
Returns:
- list
Une liste contenant toutes les données étant rattachées à une date correspondant au jour de la semaine voulu. Les données sont l'intensité et les coordonnées auxquelles elle est liée.
"""
Lundi=[]
Mardi=[]
Mercredi=[]
Jeudi=[]
Vendredi=[]
Samedi=[]
Dimanche=[]
for i in range (len(donnees_utiles)):
date=datetime.strptime(donnees_utiles[i][1], '%Y-%m-%d')
jour=date.weekday()
if jour==0:
Lundi.append([donnees_utiles[i][0], donnees_utiles[i][2]])
elif jour==1:
Mardi.append([donnees_utiles[i][0], donnees_utiles[i][2]])
elif jour==2:
Mercredi.append([donnees_utiles[i][0], donnees_utiles[i][2]])
elif jour==3:
Jeudi.append([donnees_utiles[i][0], donnees_utiles[i][2]])
elif jour==4:
Vendredi.append([donnees_utiles[i][0], donnees_utiles[i][2]])
elif jour==5:
Samedi.append([donnees_utiles[i][0], donnees_utiles[i][2]])
else:
Dimanche.append([donnees_utiles[i][0], donnees_utiles[i][2]])
if j==0:
return Lundi
elif j==1:
return Mardi
elif j==2:
return Mercredi
elif j==3:
return Jeudi
elif j==4:
return Vendredi
elif j==5:
return Samedi
else:
return Dimanche
coor_unique(j)
Description:
La fonction extrait toutes les coordonnées prises sur un jour j de façon unique.
Paramètre:
- j (int) : Le numéro du jour de la semaine (entre 0 et 6) voulu.
Retourne:
- L (list) : Une liste contenant toutes les coordonnées apparaissant dans les données prises un jour de la semaine j de façon unique.
Code de la fonction:
def coor_unique(j):
"""
Description:
La fonction 'coor_unique' extrait toutes les coordonnées prises sur un jour j de façon unique.
Paramètre:
j : int
Le numéro du jour de la semaine (entre 0 et 6) voulu.
Retourne:
list
Une liste contenant toutes les coordonnées apparaissant dans les données prises un jour de la semaine j de façon unique.
"""
L=jour_semaine(j)
co=[]
for i in L:
if i[1] not in co:
co.append(i[1])
return co
nb_tot_jour(j)
Description:
La fonction renvoie le nombre de dates comptées dans les donnnées correspondants au jour de la semaine j.
Paramètre:
- j (int): Le numéro du jour de la semaine (entre 0 et 6) voulu.
Retourne:
- len(D) (int): Le nombre de jour j comptés dans les données.
Code de la fonction:
def nb_tot_jour(j):
"""
Description:
La fonction 'nb_tot_jour' renvoie le nombre de dates comptées dans les donnnées correspondants au jour de la semaine j.
Args:
- j : int
Le numéro du jour de la semaine (entre 0 et 6) voulu.
Returns:
- int
Le nombre de jour j comptés dans les données.
"""
D=[]
for file in files:
with open(file, 'r', encoding='utf-8') as f:
lecteur = csv.reader(f, delimiter=',') # Définir le séparateur si nécessaire
next(lecteur) # Ignorer l'entête
for ligne in lecteur:
dat, heur = ligne[0].split(' ')
date=datetime.strptime(dat, '%Y-%m-%d')
jour=date.weekday()
if jour==j:
dep=ligne[1].split(' ')[0]
arr=ligne[2].split(' ')[0]
if dep!='' and arr!='':
if dep in Sta and arr in Sta:
if dat not in D:
D.append(dat)
return len(D)6.2.2 Prédiction
mean_intens(j)
Description:
La fonction renvoie une liste des moyennes des intensités par coordonnées mesurées à une date correspondant au jour de la semaine j.
Paramètres:
- j (int) : Le numéro du jour de la semaine (entre 0 et 6) voulu.
Retourne:
- L (list) : Une liste contenant toutes les moyennes d’intensité et les coordonnées auxquelles elle sont liées.
Code de la fonction:
def mean_intens(j):
"""
Description:
La fonction 'mean_intens' renvoie une liste des moyennes des intensités par coordonnées mesurées à une date correspondant au jour de la semaine j.
Args:
j : int
Le numéro du jour de la semaine (entre 0 et 6) voulu.
Returns:
list
Une liste contenant toutes les moyennes d'intensité et les coordonnées auxquelles elle sont liées.
"""
N=0
L=jour_semaine(j)
M=[]
for i in L:
N=0
sum=i[0]
n=0
k=0
for h in L:
if h[1]==i[1]:
sum+=h[0]
N+=1
if len(M)>0:
while n==0 and k<len(M):
if i[1]==M[k][1]:
n=1
k+=1
if n==0:
i[0]=sum/N
M.append(i)
return M Exemple d’utilisation: Supposons que les données soient:
coordinate, date, intensity
[3.48, 43.8], 2022-03-12, 26
[3.47, 43.7], 2022-03-19, 32
[3.48, 43.8], 2202-03-19, 15Comme le 12 et le 19 mars 2022 sont des samedis: Appeler mean_intens(5) retourne [[[3.48, 43.8], 20.5], [[3.47, 43.7], 32]]
poids_par_h(j)
Description:
La fonction compte la participation de chaque heure dans la journée. Elle donne la proportion de l’activité journalière calculée par heure pour le jour de la semaine j.
Paramètre:
- j (int): Le numéro du jour de la semaine (entre 0 et 6) voulu.
Retourne:
- `` (matrix): Une matrice avec pour colonne les heures et le pourcentage de l’activité journalière associée à chacune de ces heures.
Code de la fonction:
def poids_par_h(j):
"""
Description:
La fonction 'poids_par_h' compte la participation de chaque heure dans la journée. Elle donne la proportion de l'activité journalière calculée par heure pour le jour de la semaine j.
Args:
- j : int
Le numéro du jour de la semaine (entre 0 et 6) voulu.
Returns:
- matrix
Une matrice avec pour colonne les heures et le pourcentage de l'activité journalière associée à chacune de ces heures.
"""
heures = {heure: 0 for heure in range(24)}
D=[]
for file in files:
with open(file, 'r', encoding='utf-8') as f:
lecteur = csv.reader(f, delimiter=',')
next(lecteur) #ignorer l'entête
for ligne in lecteur:
dat = ligne[0].split(' ')[0]
heur =ligne[0].split(' ')[1]
date=datetime.strptime(dat, '%Y-%m-%d')
jour=date.weekday()
if jour==j:
dep=ligne[1].split(' ')[0]
arr=ligne[2].split(' ')[0]
if dep!='' and arr!='':
if dep in Sta and arr in Sta:
if dat not in D:
D.append(dat)
heure = int(heur.split(':')[0]) # Extraire l'heure
heures[heure] += 1 # Incrémenter le compteur pour cette heure
N=len(D)
H=[heures[h]/N for h in heures]
t=sum(H[h] for h in heures)
return [[h, H[h]*100/t] for h in heures]Exemple d’utilisation: Supposons qu’il y ait 750 trajets un jeudi dont 300 entre midi et 13h, 200 entre 18h et 19h et 250 entre 8h et 9h
Appeler poids_par_heure retourne [[0, 0],[1, 0],[2, 0],[3, 0],[4, 0],[5, 0], [6, 0],[7, 0], [8, 33.33], [9, 0],[10, 0],[11, 0],[12, 40],[13, 0],[14, 0],[15, 0],[16, 0],[17, 0],[18, 26.66],[19, 0],[20, 0],[21, 0],[22, 0],[23, 0]]
trajets_parcourus(j, h)
Description:
La fonction recense les trajets ayant eut lieu un jour j à une heure h et leur occurence.
Paramètres:
- j (int): Le numéro du jour de la semaine (entre 0 et 6) voulu.
- h (int): Le numéro de l’heure (entre 0 et 23) voulue.
Retourne:
- F (matrix): Une matrice avec chaque ligne de la forme [[station de départ, station d’arrivée], occurrence]
Code de la fonction:
def trajets_parcourus(j,h):
"""
Description:
La fonction 'trajets_parcourus' recense les trajets ayant eu lieu un jour j à une heure h et leur occurence.
Args:
- j : int
Le numéro du jour de la semaine (entre 0 et 6) voulu.
- h : int
Le numéro (de 0 à 23) de l'heure voulue.
Returns:
- matrix
Une matrice avec chaque ligne de la forme [[station de départ, station d'arrivée], occurrence]
"""
D=trajets_parcourus_jour(j)
T=[]
U=[]
F=[]
for j in D:
H=int(j[0].split(':')[0])
if H==h:
T.append([j[1],j[2]])
for I in T:
if I not in U:
U.append(I)
for s in U:
c=0
for t in T:
if t==s:
c+=1
F.append([s,c])
return FExemple d’utilisation: Supposons qu’il y ait 25 trajets un jeudi entre midi et 13h faisant Comédie-Fac des sciences Appeler trajets_parcourus(3, 12) retourne une matrice dont l’une des lignes est [['Comédie', 'Fac des sciences'], 25]
TRAJETS(j, h)
Description:
La fonction recense les trajets ayant eut lieu un jour j à une heure h.
Paramètres:
- j (int): Le numéro du jour de la semaine (entre 0 et 6) voulu.
- h (int): Le numéro de l’heure (entre 0 et 23) voulue.
Retourne:
- T (matrix): Une matrice avec chaque ligne de la forme [station de départ, station d’arrivée].
Code de la fonction:
def TRAJETS(j, h):
"""
Description:
La fonction 'TRAJETS' recense les trajets ayant eu lieu un jour j à une heure h.
Args:
- j : int
Le numéro du jour de la semaine (entre 0 et 6) voulu.
- h : int
Le numéro (de 0 à 23) de l'heure voulue.
Returns:
- matrix
Une matrice avec chaque ligne de la forme [station de départ, station d'arrivée]
"""
T=[]
J=[Lu, Ma, Me, Je, Ve, Sa, Di]
L=J[j]
for j in L:
H=int(j[0].split(':')[0])
if H==h:
T.append([j[1], j[2]])
return T
traj_mult(j, h)
Description:
La fonction recense les trajets ayant eut lieu un jour j à une heure h et leur occurrence s’ils arrivent plus de deux fois par an.
Paramètres:
- j (int): Le numéro du jour de la semaine (entre 0 et 6) voulu.
- h (int): Le numéro de l’heure (entre 0 et 23) voulue.
Retourne:
- G (matrix): Une matrice avec chaque ligne de la forme [[station de départ, station d’arrivée], occurrence] uniquement si l’occurrence est supérieure à 8 ( 2 fois pas an).
Code de la fonction:
def traj_mult(j, h):
"""
Description:
La fonction 'trajets_mult' recense les trajets ayant eu lieu un jour j à une heure h et leur occurrence s'ils arrivent plus de deux fois par an.
Args:
- j : int
Le numéro du jour de la semaine (entre 0 et 6) voulu.
- h : int
Le numéro (de 0 à 23) de l'heure voulue.
Returns:
- matrix
Une matrice avec chaque ligne de la forme [[station de départ, station d'arrivée], occurrence] uniquement si l'occurrence est supérieure à 8 ( 2 fois pas an).
"""
T=TRAJETS(j, h)
U=[]
F=[]
G=[]
for I in T:
if I not in U:
U.append(I)
for s in U:
c=0
for t in T:
if t==s:
c+=1
F.append([s,c])
for i in F:
if i[1]>=8: # min une fois par semestre
G.append(i)
return G
trajets_parcourus_jour(j)
Description:
La fonction recense tous les trajets ayant eut lieu un jour j.
Paramètre:
- j (int): Le numéro du jour de la semaine (entre 0 et 6) voulu.
Retourne:
- D (matrix): Une matrice avec chaque ligne de la forme [heure de départ, station de départ, station d’arrivée].
Code de la fonction:
def trajets_parcourus_jour(j):
"""
Description:
La fonction 'trajets_parcourus_jour' recense tous les trajets ayant eut lieu un jour j.
Args:
- j : int
Le numéro du jour de la semaine (entre 0 et 6) voulu.
Returns:
- matrix
Une matrice avec chaque ligne de la forme [heure de départ, station de départ, station d'arrivée].
"""
D=[]
for file in files:
with open(file, 'r', encoding='utf-8') as f:
lecteur = csv.reader(f, delimiter=',') # Définir le séparateur si nécessaire
next(lecteur) #ignorer l'entête
for ligne in lecteur:
dat, heur = ligne[0].split(' ')
dep=ligne[1].split(' ')[0]
arr=ligne[2].split(' ')[0]
date=datetime.strptime(dat, '%Y-%m-%d')
jour=date.weekday()
if jour==j:
if dep in Sta and arr in Sta:
if dep!=arr:
D.append([heur, dep, arr])
return D 6.2.3 Video
chemin_court(row)
Description:
Cette fonction calcule le chemin le plus court entre deux stations à l’aide du graphe routier de Montpellier. Les coordonnées géographiques des stations sont utilisées comme points de départ et d’arrivée.
Paramètres:
- row (pandas.Series) : Une ligne issue du DataFrame contenant les coordonnées de départ et d’arrivée des trajets.
Retourne:
- chemin (list) : Une liste d’identifiants représentant le chemin optimal.
- duration (float) : La durée totale en secondes pour le trajet donné.
Code de la fonction:
def chemin_court(row):
try:
depart_lat, depart_lon = row['latitude_depart'], row['longitude_depart']
arrivee_lat, arrivee_lon = row['latitude_retour'], row['longitude_retour']
duration = row['Duration (sec.)']
noeud_deb = ox.distance.nearest_nodes(G, depart_lon, depart_lat)
noeud_fin = ox.distance.nearest_nodes(G, arrivee_lon, arrivee_lat)
chemin = nx.shortest_path(G, noeud_deb, noeud_fin, weight="length")
return chemin, duration
except Exception as e:
print(f"Erreur pour le trajet entre {row['Departure station']} et {row['Return station']}: {e}")
return None, None
```
**Exemple d'utilisation**:
Lorsqu'une ligne du DataFrame est passée, cette fonction renvoie le chemin le plus court calculé sur la base du graphe routier et la durée du trajet.
</details>
<details>
<summary>`init()`</summary>
**Description**:
Initialise l'animation en réinitialisant la position des points. Les points sont effacés pour chaque frame, leur état est remis à vide pour commencer l'animation depuis le début.
**Retourne**:
- `points (list)` : Une liste d'objets `matplotlib` représentant les points à animer.
**Code de la fonction**:
```python
def init():
for point in points:
point.set_data([], [])
return pointsExemple d’utilisation:
Cette fonction est utilisée comme étape préliminaire pour configurer l’état de l’animation avant chaque itération.
update(frame)
Description:
Met à jour dynamiquement les positions des points pour chaque frame dans l’animation. Chaque point suit sa progression en fonction de la simulation temporelle et de la base de données des trajets.
Paramètres:
- frame (int) : L’index de la frame actuelle dans la séquence d’animation.
Retourne:
- points (list) : Les nouvelles positions des points mis à jour pour l’animation.
Code de la fonction:
def update(frame):
current_time = start_time + datetime.timedelta(seconds=frame * frame_duration)
time_text.set_text(current_time.strftime('%Y-%m-%d %H:%M:%S'))
for i, path in enumerate(paths):
progress = min(frame / total_frames, 1)
num_nodes = int(progress * len(path))
if num_nodes > 0:
current_node = path[num_nodes - 1]
x, y = G.nodes[current_node]['x'], G.nodes[current_node]['y']
points[i].set_data([x], [y])
return pointsExemple d’utilisation:
Chaque frame appelée dans la boucle d’animation utilise cette fonction pour déplacer les points selon la progression de leur chemin respectif.
Contexte et Explications supplémentaires
Cette section traite du fonctionnement global :
- Les trajets sont analysés grâce à un graphe routier avec la base OSM.
- Chaque point représente un véhicule dans le réseau routier avec ses trajets correspondant à la base donnée
video_avec_coord.csv. - L’animation est synchronisée avec la base de données et simule la trajectoire temporelle.
6.3 La classe “GestionnaireDonnees”
La classe GestionnaireDonnees a été créée pour gérer le téléchargement, la lecture et le traitement des jeux de données. Elle centralise les fonctions nécessaires à la gestion des données pour notre projet, en permettant le téléchargement de fichiers depuis des URLs, l’extraction de fichiers compressés, et le chargement de fichiers CSV tout en nettoyant les données manquantes. Elle simplifie ainsi les tâches courantes liées à la gestion des données dans notre système.
La classe GestionnaireDonnees a été créée pour gérer le téléchargement, la lecture et le traitement des jeux de données. Elle permet de :
- Télécharger des fichiers depuis des URLs.
- Extraire des fichiers compressés.
- Charger des fichiers CSV tout en nettoyant les données manquantes.
Cette classe centralise les fonctions nécessaires à la gestion des données pour notre projet et offre une solution modulaire pour ces tâches.
Méthodes
__init__(repertoire_telechargement="./data")
Description:
Initialise le répertoire de téléchargement pour stocker les fichiers téléchargés. Si le répertoire n’existe pas, il sera automatiquement créé.
Paramètres:
- repertoire_telechargement (str) : Le chemin où les fichiers seront téléchargés. Par défaut, “./data”.
Retourne:
- Rien. Cette méthode configure uniquement les attributs d’instance.
Code de la fonction:
def __init__(self, repertoire_telechargement="./data"):
self.repertoire_telechargement = repertoire_telechargement
os.makedirs(self.repertoire_telechargement, exist_ok=True)Explication:
Le constructeur utilise la fonction os.makedirs pour s’assurer que le répertoire de téléchargement existe avant toute opération. Cela évite des erreurs lors des téléchargements futurs.
Exemple d’utilisation:
gestionnaire = GestionnaireDonnees()
print(gestionnaire.repertoire_telechargement) # "./data"
telecharger_fichier(url, nom_fichier)
Description:
Télécharge un fichier à partir d’une URL donnée et l’enregistre dans le répertoire de téléchargement.
Paramètres:
- url (str) : L’URL du fichier à télécharger.
- nom_fichier (str) : Le nom du fichier une fois téléchargé.
Retourne:
- chemin (str) : Le chemin complet du fichier téléchargé.
Code de la fonction:
python def telecharger_fichier(self, url, nom_fichier): chemin = pooch.retrieve( url=url, known_hash=None, fname=nom_fichier, path=self.repertoire_telechargement ) return chemin
Explication:
Cette méthode utilise pooch.retrieve pour télécharger un fichier depuis une URL et le sauvegarder dans le répertoire défini. Le chemin complet du fichier est renvoyé.
Exemple d’utilisation:
gestionnaire = GestionnaireDonnees()
chemin = gestionnaire.telecharger_fichier("https://example.com/data.csv", "data.csv")
print(chemin) # "./data/data.csv"
charger_csv(chemin_fichier, supprimer_na=True)
Description:
Charge un fichier CSV dans un DataFrame Pandas, avec la possibilité de supprimer les lignes contenant des valeurs manquantes.
Paramètres:
- chemin_fichier (str) : Le chemin du fichier CSV à charger.
- supprimer_na (bool) : Indique si les lignes contenant des valeurs manquantes doivent être supprimées (par défaut, True).
Retourne:
- dataframe (pd.DataFrame) : Le DataFrame contenant les données du fichier CSV.
Code de la fonction:
def charger_csv(self, chemin_fichier, supprimer_na=True):
dataframe = pd.read_csv(chemin_fichier)
if supprimer_na:
dataframe = dataframe.dropna()
return dataframeExplication:
Cette méthode permet de charger un fichier CSV dans un DataFrame Pandas tout en offrant la possibilité de supprimer les lignes contenant des données manquantes, garantissant ainsi la qualité des données.
Exemple d’utilisation:
gestionnaire = GestionnaireDonnees()
df = gestionnaire.charger_csv("./data/data.csv", supprimer_na=True)
print(df.head())
extraire_zip(chemin_zip, dossier_extraction=None)
Description:
Extrait le contenu d’un fichier ZIP dans un répertoire spécifié.
Paramètres:
- chemin_zip (str) : Le chemin du fichier ZIP à extraire.
- dossier_extraction (str) : Le répertoire où les fichiers extraits seront stockés. Par défaut, les fichiers sont extraits dans un sous-dossier nommé extracted dans le répertoire de téléchargement.
Retourne:
- dossier_extraction (str) : Le chemin du dossier contenant les fichiers extraits.
Code de la fonction:
def extraire_zip(self, chemin_zip, dossier_extraction=None):
if dossier_extraction is None:
dossier_extraction = os.path.join(self.repertoire_telechargement, "extracted")
os.makedirs(dossier_extraction, exist_ok=True)
with zipfile.ZipFile(chemin_zip, 'r') as zip_ref:
zip_ref.extractall(dossier_extraction)
os.remove(chemin_zip)
return dossier_extractionExplication:
Cette méthode extrait un fichier ZIP dans un répertoire spécifié ou, si aucun répertoire n’est précisé, dans un sous-dossier nommé extracted. Après extraction, le fichier ZIP est supprimé pour économiser de l’espace disque.
Exemple d’utilisation:
gestionnaire = GestionnaireDonnees()
chemin_extraction = gestionnaire.extraire_zip("./data/archive.zip")
print(chemin_extraction) # "./data/extracted/"En résumé, la classe GestionnaireDonnees centralise les opérations courantes liées à la gestion des données dans notre projet, rendant le processus plus fluide et réutilisable. Elle offre des méthodes pour télécharger des fichiers, charger des données à partir de CSV et extraire des fichiers ZIP, ce qui constitue la base de notre système de traitement des données.
7. Tests
7.1 Introduction
Les tests jouent un rôle essentiel dans le développement du projet CycleVision3. Ils garantissent la fiabilité des modules, réduisent les risques d’erreurs et assurent une qualité élevée du code. Dans ce projet, nous avons mis l’accent sur les tests unitaires, couvrant les principaux composants fonctionnels.
7.2 Organisation des tests
Les tests jouent un rôle essentiel dans le développement du projet CycleVision3 en garantissant la fiabilité des modules, en réduisant les risques d’erreurs et en assurant une qualité élevée du code. Un accent particulier a été mis sur les tests unitaires, couvrant des fonctionnalités clés telles que le traitement des données, la gestion via des classes spécifiques, la génération de cartes interactives, les prédictions algorithmiques, l’analyse statistique et la visualisation vidéo.
Pour organiser ces tests, un répertoire tests/ a été créé. Ce dernier contient plusieurs fichiers, chacun dédié à un module particulier du projet :
test_donnée.py: Tests des fonctions dansdonnée.py;
test_gestion_donnee.py: Tests de la classeGestionnaireDonneesdansgestion_donnee.py;
test_map.py: Tests des fonctionnalités de création de cartes dansmap.py;
test_prediction.py: Tests des algorithmes de prédiction ;
test_statistique.py: Tests des fonctions statistiques destatistique.py;
test_video.py: Tests des outils de traitement vidéo dansvideo.py.
Cette organisation garantit une bonne couverture et une séparation claire des préoccupations, tout en facilitant le suivi et le débogage des différentes fonctionnalités du projet.
7.3 Description des tests par fichier
test_donnée.py
Objectif : Valider les fonctions liées au traitement et à la gestion des fichiers de données brutes.
Scénarios principaux :
- Téléchargement de fichiers depuis une URL spécifiée ;
- Chargement et validation des fichiers CSV, incluant la vérification du contenu ;
- Extraction correcte des fichiers compressés au format ZIP.
Tests inclus :
test_telecharger_fichier- But : Vérifier la capacité de la méthode
telecharger_fichierà télécharger un fichier depuis une URL et à le sauvegarder localement.
- Critères de succès :
- Le fichier est téléchargé sans erreurs ;
- Le chemin du fichier téléchargé est retourné correctement.
- Le fichier est téléchargé sans erreurs ;
- But : Vérifier la capacité de la méthode
test_charger_csv- But : Tester la méthode
charger_csvpour s’assurer que les fichiers CSV sont correctement chargés en tant que DataFrame.
- Critères de succès :
- Le DataFrame n’est pas vide ;
- Les dimensions du DataFrame et les noms des colonnes correspondent aux attentes.
- Le DataFrame n’est pas vide ;
- But : Tester la méthode
test_extraire_zip- But : Valider la méthode
extraire_zippour extraire correctement les fichiers contenus dans une archive ZIP.
- Critères de succès :
- Les fichiers extraits sont présents dans le répertoire cible ;
- Le contenu de l’archive correspond aux attentes (par exemple,
test.csvest extrait correctement).
- Les fichiers extraits sont présents dans le répertoire cible ;
- But : Valider la méthode
test_gestion_donnee.py
Objectif : Valider les fonctionnalités du gestionnaire de données, implémentées dans la classe
GestionnaireDonnees.Scénarios principaux :
- Vérification de la méthode de chargement des fichiers CSV dans un DataFrame ;
- Validation des structures des données et de leur contenu après chargement.
Tests inclus :
test_charger_csv- But : Tester la méthode
charger_csvpour s’assurer qu’elle charge correctement un fichier CSV en tant que DataFrame Pandas.
- Critères de succès :
- Le DataFrame résultant n’est pas vide ;
- La structure (dimensions et colonnes) du DataFrame correspond aux attentes ;
- Aucune erreur n’est générée lors du traitement d’un fichier CSV valide.
- Le DataFrame résultant n’est pas vide ;
- But : Tester la méthode
test_map.py
Objectif : Valider les fonctions liées à la gestion des cartes interactives et des trajets en utilisant des graphes.
Scénarios principaux :
- Conversion correcte des nœuds d’un trajet en coordonnées géographiques ;
- Création d’un graphe urbain à partir de données géographiques spécifiques.
Tests inclus :
test_route_to_coords- But : Vérifier que la fonction
route_to_coordsconvertit correctement une séquence de nœuds de graphe en une liste de coordonnées géographiques.
- Critères de succès :
- Les coordonnées générées correspondent exactement aux nœuds fournis ;
- Les données de position (latitude, longitude) sont correctement extraites des attributs du graphe.
- Les coordonnées générées correspondent exactement aux nœuds fournis ;
- But : Vérifier que la fonction
test_graph_creation- But : Tester la génération d’un graphe à partir des données géographiques d’une ville en utilisant la bibliothèque OSMnx.
- Critères de succès :
- Le graphe créé contient au moins un nœud ;
- Aucun problème de récupération des données OSM n’est rencontré.
- Le graphe créé contient au moins un nœud ;
- But : Tester la génération d’un graphe à partir des données géographiques d’une ville en utilisant la bibliothèque OSMnx.
test_prediction.py
Objectif : Valider les fonctions liées aux prévisions d’intensité du trafic cycliste et l’analyse selon les jours spécifiques.
Scénarios principaux :
- Vérification des valeurs renvoyées par la fonction
jour_semainepour un jour donné ;
- Validation de la fonction
coor_uniquepour extraire les coordonnées uniques en fonction d’un jour ;
- Vérification de la cohérence de la moyenne d’intensité avec la fonction
mean_intens.
- Vérification des valeurs renvoyées par la fonction
Tests inclus :
test_jour_semaine- But : Vérifier que la fonction
jour_semainerenvoie correctement les données correspondant au jour spécifique (ici, mercredi).
- Critères de succès :
- Les valeurs des données attendues doivent correspondre exactement aux données simulées.
- But : Vérifier que la fonction
test_coor_unique- But : Tester la fonction
coor_uniquepour extraire correctement les coordonnées uniques correspondant à un jour spécifique (ici, vendredi).
- Critères de succès :
- Les coordonnées extraites doivent correspondre exactement aux valeurs attendues.
- But : Tester la fonction
test_mean_intens- But : Vérifier la bonne estimation de la moyenne d’intensité avec la fonction
mean_intenspour un jour donné (ici, mercredi).
- Critères de succès :
- La longueur des résultats doit correspondre aux valeurs attendues ;
- Les valeurs numériques doivent être proches des valeurs simulées avec une précision acceptable.
- La longueur des résultats doit correspondre aux valeurs attendues ;
- But : Vérifier la bonne estimation de la moyenne d’intensité avec la fonction
test_statistique.py
Objectif : Valider le traitement des données, la sauvegarde de graphiques et la gestion d’erreurs dans le traitement des données pour les visualisations statistiques.
Scénarios principaux :
- Vérification du traitement des données avec des opérations de groupe ;
- Validation de la sauvegarde d’un graphique en barres avec Matplotlib ;
- Test de la sauvegarde d’un graphique polaire avec Plotly ;
- Vérification de la gestion des erreurs avec un fichier inexistant.
- Vérification du traitement des données avec des opérations de groupe ;
Tests inclus :
test_process_data- But : Tester la transformation des données, notamment la conversion de la colonne
Departureen datetime et la création de la nouvelle colonneDate.
- Critères de succès :
- La conversion doit réussir sans erreur ;
- Les valeurs dans la colonne
Datedoivent correspondre correctement aux dates extraites.
- La conversion doit réussir sans erreur ;
- But : Tester la transformation des données, notamment la conversion de la colonne
test_save_bar_chart- But : Tester la sauvegarde d’un graphique en barres avec Matplotlib.
- Critères de succès :
- Vérifier que la fonction
savefiga bien été appelée avec le chemin attendu.
- Vérifier que la fonction
- But : Tester la sauvegarde d’un graphique en barres avec Matplotlib.
test_save_polar_chart- But : Tester la sauvegarde d’un graphique polaire avec Plotly.
- Critères de succès :
- Vérifier que la fonction
write_htmlest bien appelée avec le chemin attendu.
- Vérifier que la fonction
- But : Tester la sauvegarde d’un graphique polaire avec Plotly.
test_missing_file- But : Vérifier que l’ouverture d’un fichier inexistant génère une erreur correcte (
FileNotFoundError).
- Critères de succès :
- L’erreur doit être déclenchée correctement lorsqu’un fichier absent est tenté d’être lu avec
pd.read_csv.
- L’erreur doit être déclenchée correctement lorsqu’un fichier absent est tenté d’être lu avec
- But : Vérifier que l’ouverture d’un fichier inexistant génère une erreur correcte (
test_video.py
Objectif : Tester le module vidéo de
Cycle3/video/video.py, en se concentrant sur les aspects de traitement des données, la création et le test de graphes, la gestion de la logique avec les chemins, l’animation et la gestion des interactions avec l’utilisateur.Scénarios principaux :
- Vérifier la bonne conversion et le traitement de données ;
- Tester le module de chemin court avec OSMnx et NetworkX ;
- Simuler la création de graphes pour analyser la carte ;
- Vérifier la sauvegarde de vidéos avec Matplotlib ;
- Simuler l’interaction avec des fonctions utilisant
input().
- Vérifier la bonne conversion et le traitement de données ;
Tests inclus :
test_video_module- But : Charger dynamiquement le module vidéo
video.pypour permettre les tests avec un environnement simulé.
- Critères de succès :
- Le module doit être chargé correctement avec
importlib.util.spec_from_file_location.
- Tester l’existence des fonctions attendues (
chemin_court,init,update).
- Le module doit être chargé correctement avec
- But : Charger dynamiquement le module vidéo
test_data_processing- But : Valider la bonne lecture et conversion des données de test.
- Critères de succès :
- Vérifier que la colonne
Departureest convertie en datetime.
- Assurer que le DataFrame simulé est non vide.
- Vérifier que la colonne
- But : Valider la bonne lecture et conversion des données de test.
test_chemin_court- But : Simuler le calcul du chemin le plus court avec OSMnx et NetworkX.
- Critères de succès :
- Vérifier que le chemin attendu est renvoyé.
- Confirmer la valeur de durée correspondante.
- Vérifier que le chemin attendu est renvoyé.
- But : Simuler le calcul du chemin le plus court avec OSMnx et NetworkX.
test_create_graph- But : Valider la création de graphes avec OSMnx.
- Critères de succès :
- Vérifier que le graphe est bien de type
nx.MultiDiGraph.
- Assurer que le graphe n’est pas vide après la création.
- Vérifier que le graphe est bien de type
- But : Valider la création de graphes avec OSMnx.
test_input_handling- But : Simuler l’interaction avec
input()pour vérifier le flux de l’entrée utilisateur.
- Critères de succès :
- S’assurer que
input()est bien simulé avec la valeur attendue.
- S’assurer que
- But : Simuler l’interaction avec
test_save_video- But : Tester la logique de sauvegarde avec Matplotlib pour les animations.
- Critères de succès :
- Vérifier que l’animation est simulée correctement sans appels non nécessaires à la fonction
save.
- Confirmer que la sauvegarde n’a pas été appelée avant la logique de test.
- Vérifier que l’animation est simulée correctement sans appels non nécessaires à la fonction
- But : Tester la logique de sauvegarde avec Matplotlib pour les animations.
7.4 Résultats des tests
Tous les modules ont été testés avec succès, et les bugs identifiés ont été corrigés. Une couverture élevée des fonctionnalités a été obtenue grâce à une série de tests unitaires exécutés avec l’outil pytest.
La commande suivante permet d’exécuter tous les tests :
pytest tests/7.5 Conclusion
Les tests réalisés ont permis de valider la majorité des fonctionnalités critiques du projet. Toutefois, des améliorations supplémentaires pourraient être envisagées, notamment pour couvrir des cas d’utilisation moins fréquents ou des scénarios extrêmes.
8. Analyse des performances
#### Étude du temps et de la mémoire
Les performances ont été analysées sur un PC équipé d’une puce Apple M1.
À l’aide du package memory-profiler, il est possible de suivre la consommation de temps et de mémoire d’une fonction Python. Cependant, cette méthode ne permet pas d’analyser de tels critères sur des fichiers Quarto. Les tests réalisés sur les fichiers vidéo.py et map_trajet_BD.py à l’aide de la commande mprof run ont donné les graphiques suivants :
8.1 Pour map_trajet_BD.py
Après avoir exécuté la commande mprof run, nous avons obtenu les graphiques suivants. Le premier a été généré en traçant environ une centaine de trajets, tandis que le second illustre un tracé comportant environ 600 trajets.
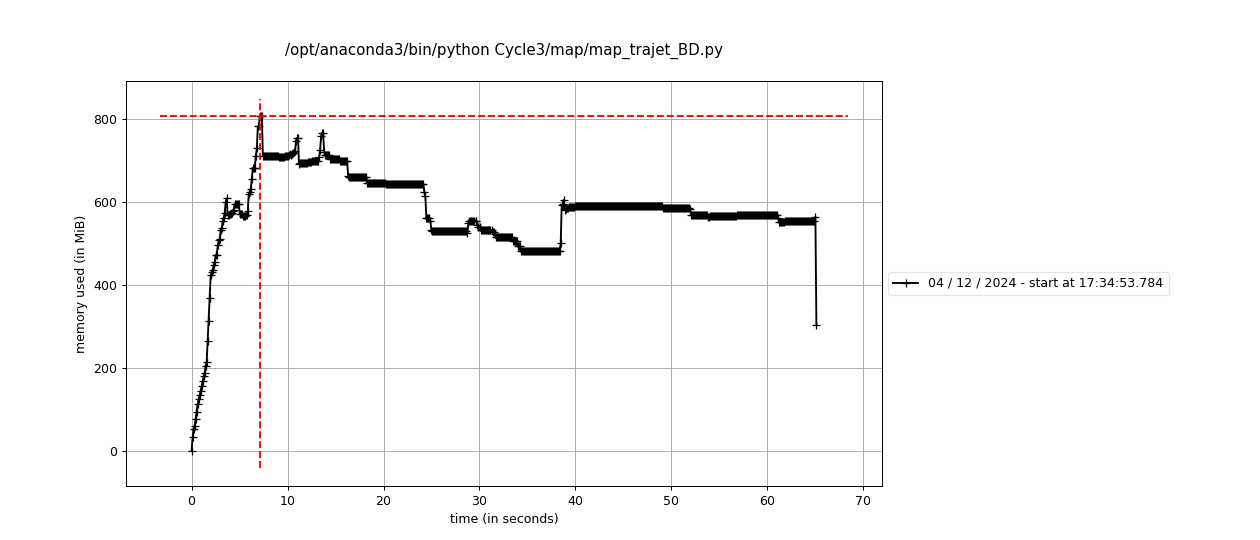
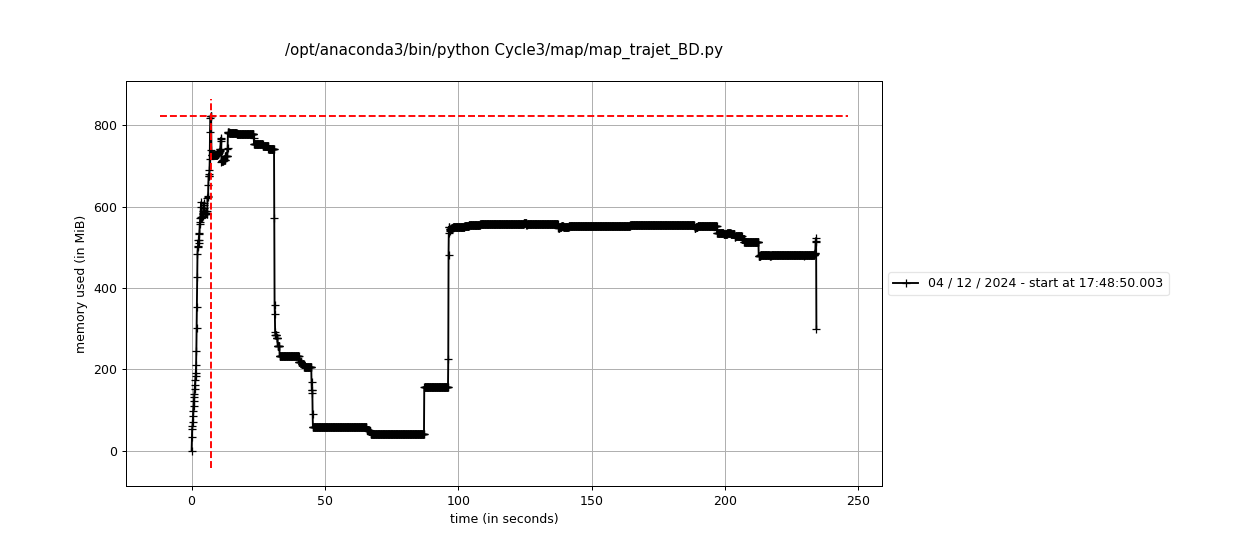
Dans cette section du code, on observe qu’un tracé de 500 trajets différents entraîne un écart de temps de 175 secondes, soit presque 3 minutes. Le temps d’exécution du fichier varie donc entre 1 minute (pour les jours avec moins de trajets) et 3 minutes (pour les jours les plus chargés). En ce qui concerne la mémoire utilisée, elle reste stable autour de 800 mébioctets (environ 800 Mo) par fichier Python. Ce chiffre est cohérent avec les machines modernes, mais pourrait devenir un facteur limitant sur des machines plus anciennes.
8.2 Pour vidéo.py
Après avoir exécuté la commande mprof run, les graphiques suivants ont été obtenus. Ceux-ci correspondent à des fichiers avec un nombre variable de trajets, allant de 100 à 600 trajets.
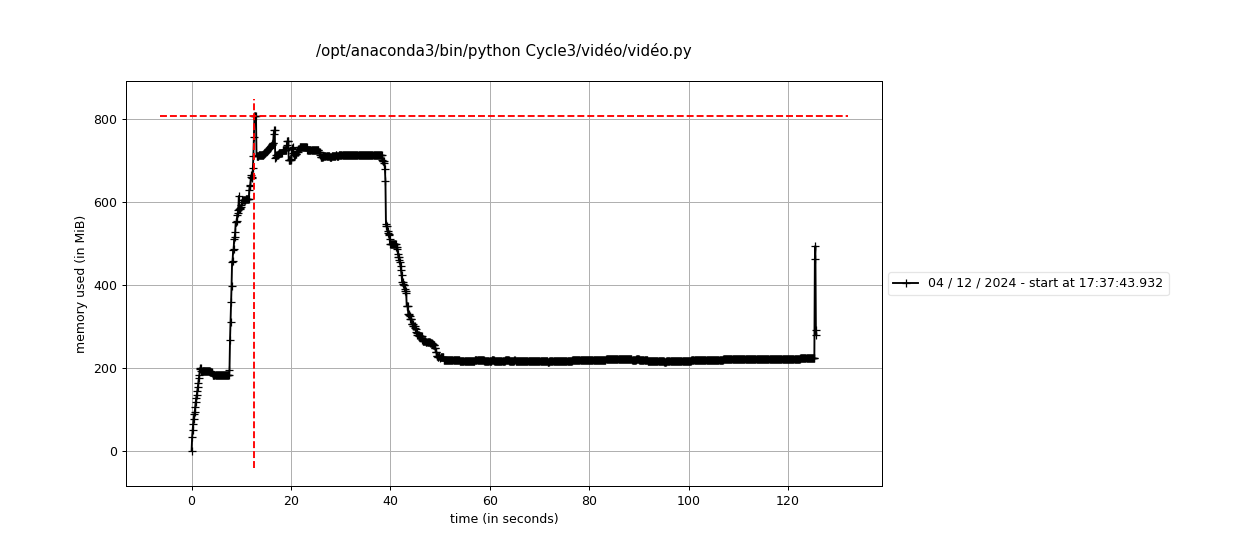
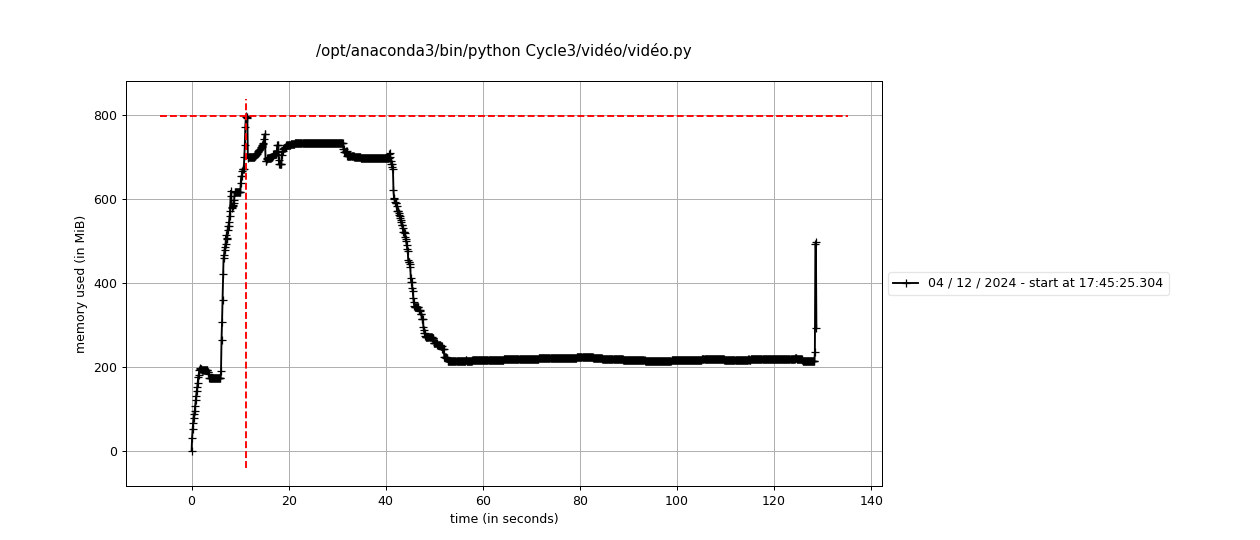
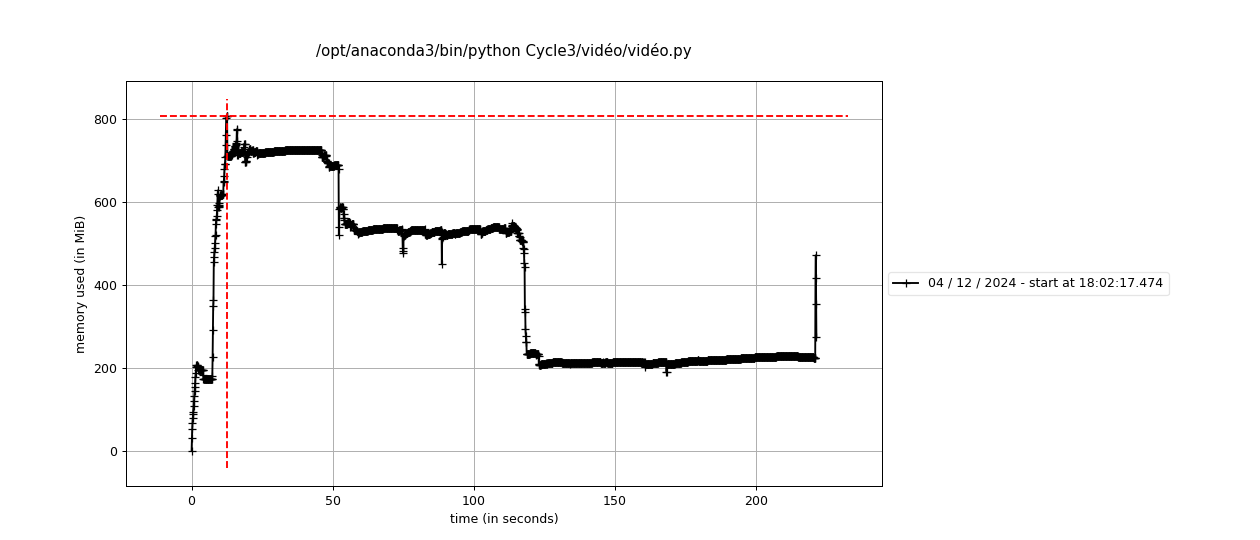
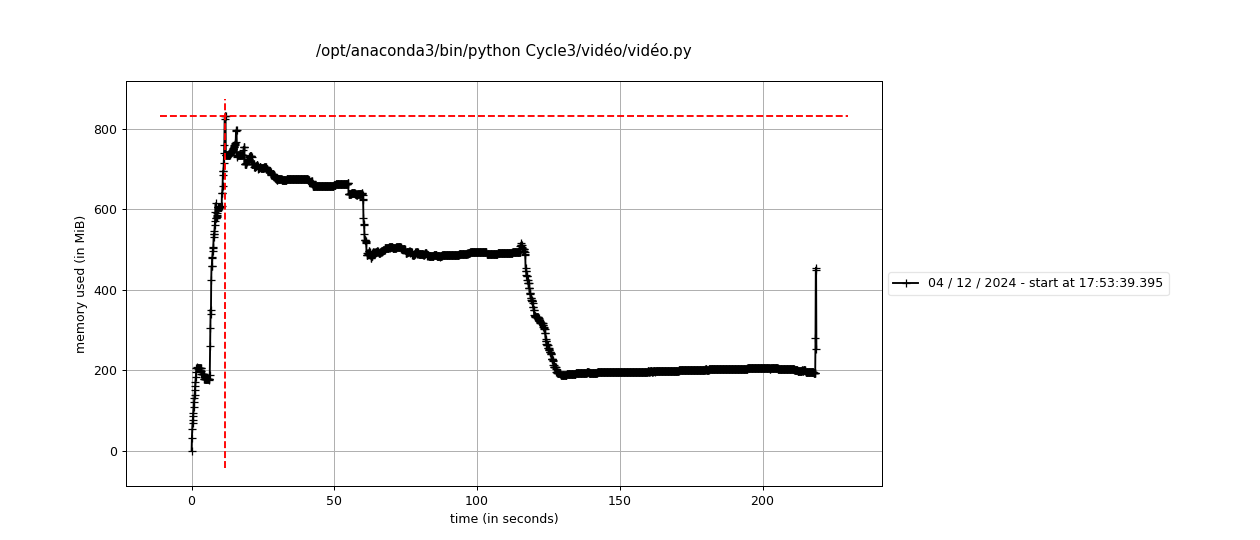
Ici, la consommation de mémoire reste similaire à celle du fichier précédent. Cependant, la différence réside dans le temps d’exécution. Malgré les tentatives d’optimisation du script, celui-ci s’exécute en environ 130 à 225 secondes pour charger une vidéo en format .mp4.
8.3 Conclusion
Concernant l’efficacité temporelle, plusieurs problèmes ont été rencontrés lors des premiers essais. Pour y remédier, des outils tels que ThreadPoolExecutor et l’utilisation de cache ont été mis en place. De plus, un choix stratégique a été fait en privilégiant l’importation directe des bases de données, plutôt que de les appeler via des requêtes HTTP avec requests, afin d’améliorer la vitesse d’exécution.
9. Guide de l’utilisateur
Avant de commencer le développement et l’analyse des données, vous devez configurer l’environnement de travail en installant toutes les dépendances nécessaires. Ce guide vous explique comment utiliser notre projet, lancer les commandes nécessaires et accéder aux résultats générés. Suivez ces étapes pour préparer le projet :
9.1 Clone du répertoire Github
Pour accéder au projet et à sa structure, commencez par cloner notre répertoire GitHub.
git clone https://github.com/mscaia/PROJ_HAX712X.git
cd ./PROJ_HAX712X9.2 Installation des packages nécessaires
On vous conseille de créer un environnement virtuel, il permet d’isoler les dépendances d’un projet, d’éviter les conflits de versions, et de garantir un contrôle simple sur les paquets installés. Il assure la reproductibilité du projet, facilite la gestion des dépendances, et protège votre système.
conda create --name Cycle3 python=3.9.18
conda activate Cycle3Ensuite, installez les packages nécessaires pour faire fonctionner le projet :
pip install -r requirements.txtAprès cette commande, l’environnement virtuel Cycle3 occupera environ 1 Go de votre espace. Vous êtes maintenant prêt à utiliser notre projet avec tous les packages nécessaires.
9.4 Création et utilisation du site
Voici quelques étapes pour la création et l’utilisation d’un site Quarto comme celui que nous avons créé.
- Installation de Quarto
Téléchargez et installez Quarto depuis quarto.org/download. Prenez bien soin d’ajouter Quarto à vos variables d’environnements.
- Création du projet
Puis, ouvrez un terminal et exécutez les commandes suivantes :
mkdir docs
cd docs
quarto create-project nom_du_projet --type website- Ajout de contenu
- Ajoutez des fichiers .qmd dans le dossier docs pour enrichir le site.
- Modifiez le fichier _quarto.yml pour personnaliser la structure et les paramètres du site.
- Prévisualisation locale
Le site peut ensuite être lancé via la commande suivante dans le répertoire ./docs/.
quarto preview- Déploiement sur GitHub
Dans les paramètres de votre projet Github, allez dans GitHub Pages puis dans la section Build and Deployment. Dans l’onglet “Source” sélectionnez Deploy from a branch et en dessous sélectionnez la branche main et le dossier docs. Vous pouvez ensuite taper les commandes suivantes (toujours dans le répertoire ./docs/) dans un terminal :
quarto renderLe site sera alors déployé à votre prochain push !
9.5 Suppression de l’environnement virtuel
Si vous n’avez plus besoin de l’environnement virtuel et souhaitez le supprimer définitivement, suivez les étapes ci-dessous :
- Désactivez l’environnement
conda deactivate- Supprimez l’environnement Conda
conda env remove --name Cycle3- Vérifiez que l’environnement a été supprimé
conda env listSi l’environnement Cycle3 a été correctement supprimé, vous ne le verrez plus dans la liste des environnements disponibles.
10. Travaux futurs
Ce projet constitue une première étape dans l’analyse du trafic cycliste à Montpellier. Plusieurs pistes peuvent être explorées pour enrichir et élargir cette étude :
Renforcement des modèles de prédiction : Une amélioration des modèles actuels pourrait être réalisée en intégrant des données supplémentaires, comme les conditions météorologiques ou les événements locaux, afin d’obtenir des prévisions plus précises.
Ajout de données en temps réel : L’intégration de données en temps réel, telles que les flux de trafic ou les perturbations temporaires, pourrait rendre les analyses plus dynamiques et adaptées à l’évolution des conditions.
Application à d’autres contextes urbains : Étendre cette méthodologie à d’autres villes permettrait de comparer les tendances cyclistes et d’identifier des spécificités locales ou des modèles universels.
Amélioration de l’expérience utilisateur : Le site Web pourrait être enrichi de fonctionnalités interactives supplémentaires, telles que la visualisation des prévisions de trafic ou des recommandations d’itinéraires alternatifs.
Ces propositions, bien qu’ambitieuses, restent accessibles et permettent d’assurer la pertinence et la durabilité du projet tout en renforçant son impact pour les usagers et les décideurs locaux.
9.3 Comment lancer certains scripts
Tous les scripts doivent être exécutés depuis le terminal. Assurez-vous que vous êtes dans la racine du projet, nommée
PROJ_HAX712X. Dans les chemins relatifs,./fait référence à la racine du projet.9.3.1 Utilisation de notre class pour télécharger les données
Téléchargez les données nécessaires pour travailler (nous avons choisi de les laisser sur GitHub) :
9.3.2 Voir nos éléments d’analyse de données
Pour voir les éléments d’analyse des données, lancez la commande suivante :
Certaines sorties sont affichées dans le terminal (avec
print), mais les graphiques sont disponibles dans le répertoire suivant :Vous y trouverez des fichiers
.htmlet.png.9.3.3 Visualisation des cartes
Dans le dossier
./Cycle3/map/, vous trouverez trois fichiers.pydifférents pour travailler avec les cartes :carte.pyAffiche la disponibilité en temps réel des vélos dans les stations Vélomagg de Montpellier.
La carte générée est sauvegardée dans
./docs/montpellier_bike_stations_map.html.map.pyEffectue une simulation de trajet. L’interactivité se fait via le terminal
La carte générée est sauvegardée dans
./Cycle3/visualisation/carte_montpellier_trajet.html9.3.4 Création d’une vidéo
Nous avons lié les scripts
./Cycle3/map/map_trajet_BD.pyet./Cycle3/vidéo/vidéo.pypour analyser les trajets d’un jour spécifique et les transformer en vidéo.map_trajet_BD.pyLancez la commande suivante pour sélectionner le jour que vous souhaitez analyser. Vous aurez la possibilité de tracer ou non les trajets, et de définir le nombre de trajets à afficher.
La carte générée est sauvegardée dans
./Cycle3/visualisation/carte_montpellier_trajet_via_BD.htmlAttention : Ce processus peut être long. Veuillez vous référer à la section 8. Analyse des performances de la documentation pour plus d’informations. Lancez la commande suivante pour créer la vidéo :
Vous pourrez choisir le nombre de trajets à afficher. La vidéo générée sera sauvegardée dans
./Cycle3/visualisation/simulation_trajets.mp4.9.3.5 Utilisation de la prédiction
Pour lancer notre script sur la prédiction :